
实验环境:
mysql5.7
CentOS Linux release 7.3.1611 (Core)
4核8G资源
目的:主要使用python代码测试一下mysql压力以及参数调优
可以开启mysql通用日志用来调试查询sql
查看是否开启通用日志
show variables like ‘%general%’;
临时生效
开启通用日志查询: set global general_log=on;
关闭通用日志查询: set globalgeneral_log=off;
设置通用日志输出为表方式: set globallog_output=’TABLE’;
设置通用日志输出为文件方式: set globallog_output=’FILE’;
设置通用日志输出为表和文件方式:set global log_output=’FILE,TABLE’;
永久生效
my.cnf文件的配置如下:
general_log=1 #为1表示开启通用日志查询,值为0表示关闭通用日志查询
log_output=FILE,TABLE#设置通用日志的输出格式为文件和表,FILE(存储在数数据库的数据文件中的hostname.log),TABLE(存储在数据库中的mysql.general_log)
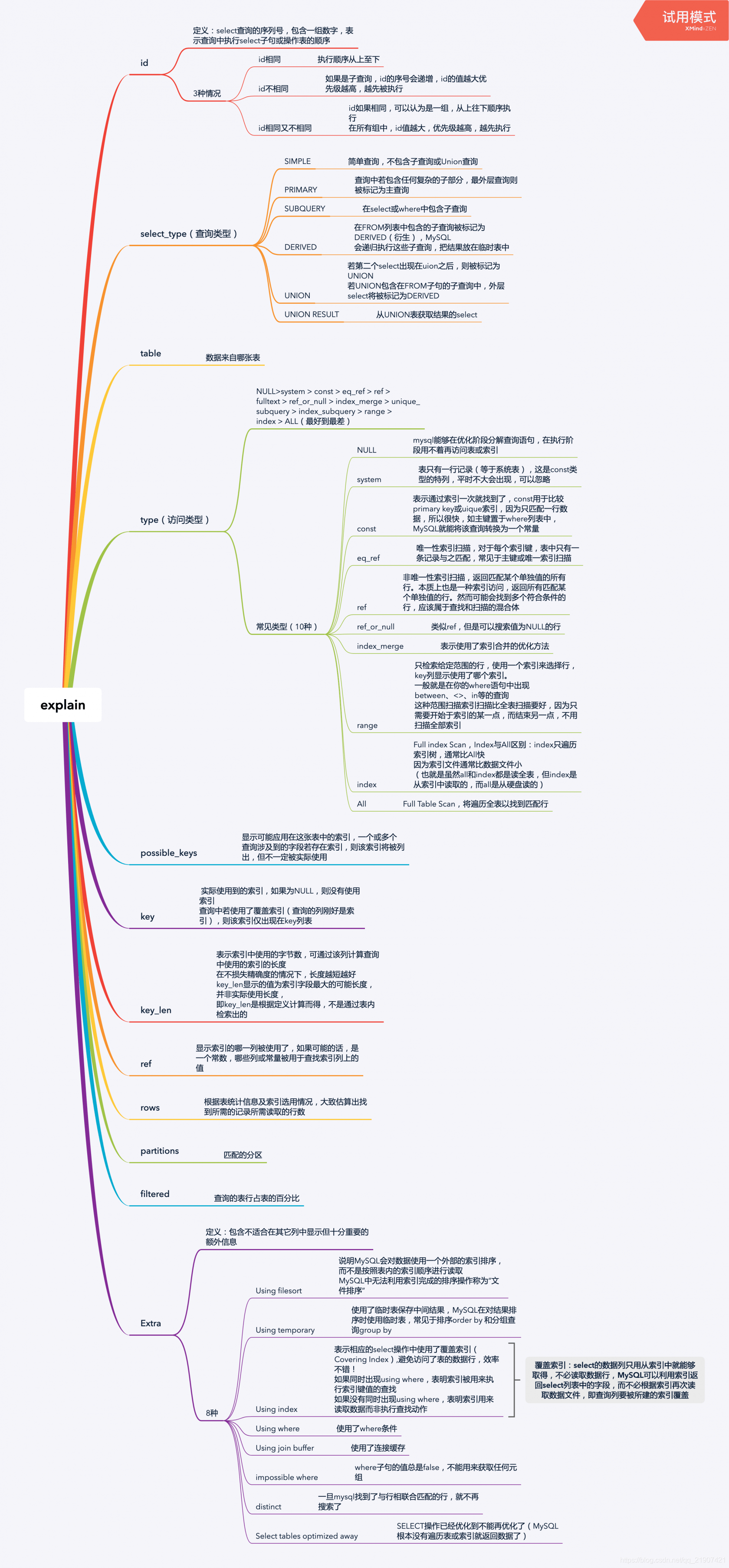
先描述一下 EXPLAIN 优化工具
EXPLAIN 后面跟sql语句 如图

字段解析
1. id //select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序 2. select_type //查询类型 3. table //正在访问哪个表 4. partitions //匹配的分区 5. type //访问的类型 6. possible_keys //显示可能应用在这张表中的索引,一个或多个,但不一定实际使用到 7. key //实际使用到的索引,如果为NULL,则没有使用索引 8. key_len //表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度 9. ref //显示索引的哪一列被使用了,如果可能的话,是一个常数,哪些列或常量被用于查找索引列上的值 10. rows //根据表统计信息及索引选用情况,大致估算出找到所需的记录所需读取的行数 11. filtered //查询的表行占表的百分比 12. Extra //包含不适合在其它列中显示但十分重要的额外信息
图片详解:
数据结构:
CREATE TABLE `student_data` ( `student_id` int(11) NOT NULL AUTO_INCREMENT, `student_name` varchar(10) DEFAULT NULL, `student_age` tinyint(4) DEFAULT NULL, `student_class` varchar(40) DEFAULT NULL, `subject` varchar(40) DEFAULT NULL, `score` tinyint(4) DEFAULT NULL, PRIMARY KEY (`student_id`), KEY `s_name` (`student_name`) ) ENGINE=InnoDB AUTO_INCREMENT=2063942 DEFAULT CHARSET=utf8;
CREATE TABLE `student_info` ( `student_id` int(11) DEFAULT NULL, `grade` int(11) DEFAULT NULL, `addr` varchar(100) DEFAULT NULL, `phone` varchar(11) DEFAULT NULL, `patriarch_phone` varchar(11) DEFAULT NULL, `teacher_id` int(11) DEFAULT NULL, KEY `sid` (`student_id`), KEY `tid` (`teacher_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `teacher_by_class` ( `teacher_id` tinyint(4) DEFAULT NULL, `class_id` tinyint(4) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `teacheres` ( `teacher_id` int(11) NOT NULL AUTO_INCREMENT, `teacher_name` varchar(40) DEFAULT NULL, `teacher_subject_id` varchar(40) DEFAULT NULL, `teacher_phone` varchar(11) DEFAULT NULL, `if_head_teacher` enum('1','0') DEFAULT '0', PRIMARY KEY (`teacher_id`) ) ENGINE=InnoDB AUTO_INCREMENT=200001 DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `class_name_zh`; CREATE TABLE `class_name_zh` ( `class_id` tinyint(4) DEFAULT NULL, `class_name_zh` varchar(40) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT INTO `class_name_zh` VALUES ('1', '一班'); INSERT INTO `class_name_zh` VALUES ('2', '二班'); INSERT INTO `class_name_zh` VALUES ('3', '三班'); INSERT INTO `class_name_zh` VALUES ('4', '四班');
压测工具
执行一次测试,分别50和100个并发,执行10w次总查询
mysqlslap -a --concurrency=50,100 --number-of-queries 100000 -uroot -p123
我这里使用50并发发送请求会导致CPU占满,而内存使用20%
当出现连接异常或者CPU,内存资源占满时应该调整参数
使用python代码连接压测
import pymysql
import sys
import random
import threading
class MysqlCustom():
def __init__(self,db_name):
self.db = pymysql.connect(host="127.0.0.1", user="test",passwd="test123", db=db_name)
self.cursor = self.db.cursor()
def select(self,sql):
try:
self.db.ping(reconnect=True)
self.cursor.execute(sql)
result = self.cursor.fetchall()
if sys.version_info[0] == 2:
result = map(list, result)
else:
result = list(map(list, result))
print(result)
except Exception as e:
print(str(e))
def insert(self,cus_sql):
row=0
try:
self.db.ping(reconnect=True)
self.cursor.execute(cus_sql)
row = self.cursor.rowcount
self.db.commit()
except Exception as e:
row = "插入数据错误" +str(e)
return row
def close(self):
self.cursor.close()
self.db.close()
def tasks():
db_obj = MysqlCustom("Stress")
for i in range(1000):
i = random.randrange(20,80)
j = random.randrange(30,99)
class_id = random.choice([1,2,3,4])
db_obj.select('''select * from student_data where score BETWEEN %s and %s and student_class = %s limit 5'''%(i,j,class_id))
db_obj.close()
if __name__ == "__main__":
thread_list = []
for i in range(4):
p = threading.Thread(target=tasks)
thread_list.append(p)
for thread in thread_list:
thread.setDaemon(True)
thread.start()
for thread in thread_list:
thread.join()
默认使用4个线程去测试,未添加索引score时,每个查询都会使用1s左右,会把cpu占满,此时qps为20左右,添加索引后,每个查询都是0.01s,无占用cpu
初步判断 当有慢查询时,即使并发不高的情况,也会导致cpu爆满
mysql参数配置
2-4G 内存 建议
[mysqld] binlog_cache_size = 64K thread_stack = 256K join_buffer_size = 2048K read_rnd_buffer_size = 512K read_buffer_size = 768K sort_buffer_size = 768K thread_cache_size = 96 table_open_cache = 192 query_cache_type = 1 max_connections = 200 innodb_log_buffer_size = 32M innodb_buffer_pool_size = 384M max_heap_table_size = 384M tmp_table_size = 384M query_cache_size = 128M
4-8G 内存 建议
[mysqld] binlog_cache_size = 128K thread_stack = 256K join_buffer_size = 2048K read_rnd_buffer_size = 768K read_buffer_size = 1024K sort_buffer_size = 1024K thread_cache_size = 128 table_open_cache = 384 query_cache_type = 1 max_connections = 300 innodb_log_buffer_size = 32M innodb_buffer_pool_size = 512M max_heap_table_size = 512M tmp_table_size = 512M query_cache_size = 192M
8-16G 内存 建议
[mysqld] binlog_cache_size = 192K thread_stack = 384K join_buffer_size = 4096K read_rnd_buffer_size = 1024K read_buffer_size = 2048K sort_buffer_size = 2048K thread_cache_size = 192 table_open_cache = 1024 query_cache_type = 1 max_connections = 400 innodb_log_buffer_size = 32M innodb_buffer_pool_size = 1024M max_heap_table_size = 1024M tmp_table_size = 1024M query_cache_size = 256M
16-32G 内存建议
[mysqld] binlog_cache_size = 256K thread_stack = 512K join_buffer_size = 8192K read_rnd_buffer_size = 2048K read_buffer_size = 4096K sort_buffer_size = 4096K thread_cache_size = 256 table_open_cache = 2048 query_cache_type = 1 max_connections = 500 innodb_log_buffer_size = 32M innodb_buffer_pool_size = 4096M max_heap_table_size = 2048M tmp_table_size = 2048M query_cache_size = 384M