

在视觉语言模型(VLM)赋能下,计算机使用智能体(CUA)已能自主完成各类电脑操作任务,成为自动化办公、智能交互的核心技术方向。但目前主流 CUA 系统的核心细节均为闭源,数据、架构、训练流程的不透明不仅限制了技术迭代,还引发了安全与可解释性的担忧。
为解决这一行业痛点,香港大学 XLANG Lab 联合 Moonshot AI、斯坦福大学等机构推出了OPENCUA—— 一套全开源的 CUA 规模化构建框架,涵盖标注基础设施、大规模数据集、高效训练流水线与高性能模型,为 CUA 研究打造了开放、可复现的技术底座。
一、OPENCUA 的核心实现路径:从数据到模型的全链路开源方案

OPENCUA 的核心目标是构建可规模化、高泛化性的 CUA 体系,其实现路径围绕数据采集 - 数据处理 - 模型训练 - 评估体系四大核心环节展开,形成了从人类操作示范到智能体自主执行的端到端解决方案。
- 数据采集:AGENTNET TOOL+AGENTNET 数据集,突破 CUA 数据瓶颈
CUA 的性能高度依赖真实、多样的人类操作数据,但现有开源方案缺乏跨平台、易操作的标注工具,且数据集存在领域单一、规模不足的问题。- AGENTNET TOOL:
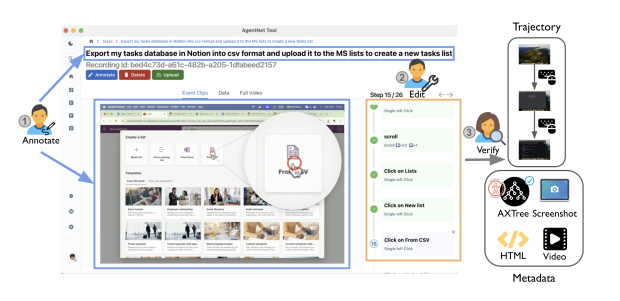
研发跨 Windows、macOS、Ubuntu 三大系统的标注工具,可在不干扰用户操作的前提下,后台实时捕获屏幕视频、键鼠操作信号、可访问性树(Axtree),并支持标注者对操作轨迹进行审核、编辑。工具放松了 “全正确操作” 的标注要求,允许存在合理错误,为后续模型的错误检测与恢复能力训练奠定基础。 - AGENTNET 数据集:
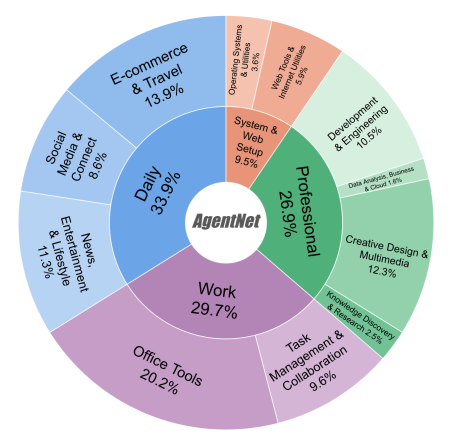
基于标注工具收集了22.6K 开放式计算机任务轨迹,覆盖 140 + 应用、190 + 网站,平均每个任务 18.6 步,包含多应用协作、专业功能使用等复杂场景。这是首个支持桌面端、跨平台、带长推理轨迹的大规模 CUA 数据集,真实还原了个人电脑环境中的人类操作行为。
同时,为解决线上评估成本高、复现难的问题,OPENCUA 基于数据集构建了AGENTNETBENCH离线基准,包含 100 个代表性任务,为每个步骤提供多个有效操作选项,更贴合真实场景的决策多样性,且与线上评估结果高度相关,大幅提升模型迭代效率。
- AGENTNET TOOL:
- 数据处理:从原始操作到结构化轨迹,注入反思式长链推理
原始人类操作包含大量高频、冗余的键鼠动作(如连续鼠标移动),直接用于训练会导致模型效率低下;且单纯的 “状态 - 动作” 对难以支撑模型的复杂推理。OPENCUA 设计了两层关键处理流程:- 动作离散化与轨迹压缩:通过动作约简将原子键鼠操作合并为高维语义动作(如将连续按键合并为文本输入、鼠标移动 + 点击合并为单次点击),并通过状态 - 动作匹配为每个动作匹配对应的屏幕关键帧,构建紧凑的「状态 - 动作」对,大幅降低训练数据的冗余度。
- 反思式长链推理(Reflective Long CoT)合成:这是 OPENCUA 的核心创新之一。
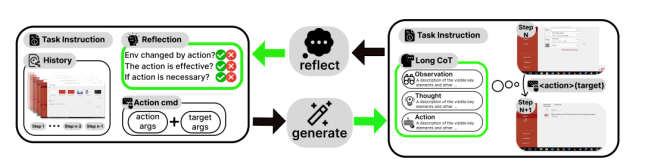
在「状态 - 动作」对基础上,注入三层结构化推理逻辑:L3(上下文观察,提取屏幕关键视觉 / 文本信息)→L2(反思式推理,分析状态变化、回忆历史步骤、纠正错误、规划下一步)→L1(可执行动作,基于推理输出具体操作)。同时设计反射器 - 生成器 - 总结器流水线,让模型能识别人类操作中的错误并生成反思推理,赋予模型错误检测与恢复能力。
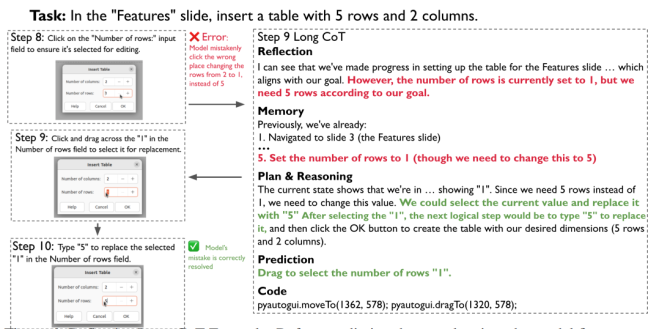
- 模型训练:多维度优化,实现数据与模型的双规模化
OPENCUA 基于主流开源视觉语言模型(Qwen2.5-VL、Kimi-VL-A3B)进行有监督微调(SFT),从上下文编码、训练数据混合、训练策略三个维度优化,让模型性能随数据规模、模型参数量实现线性提升:- 上下文编码:采用「L1 CoT 文本历史 + 3 张截图视觉历史」的组合,在保证训练效率的前提下,为模型提供足够的历史上下文信息,支撑长程任务推理。
- 训练数据混合:融合三层 CoT 数据(L1/L2/L3)、GUI 定位数据、通用视觉语言数据,既保证模型的计算机操作能力,又提升其通用推理与指令理解能力;
- 多阶段训练策略:提供三种训练方案适配不同算力需求 —— 仅第二阶段微调(轻量适配,保留通用能力)、两阶段训练(先定位后规划,性能更优)、联合训练(构建通用 VLM+CUA 能力),让不同研究团队都能基于 OPENCUA 进行二次开发。
- 评估体系:多维度验证,覆盖线上执行、线下推理、GUI 定位
为全面验证模型能力,OPENCUA 构建了多维度评估体系,涵盖:- 线上执行评估:基于 OSWorld-Verified(369 个验证后的跨平台任务)、WindowsAgentArena(154 个 Windows 专属任务),测试模型在真实环境中的端到端执行能力;
- 线下推理评估:基于 AGENTNETBENCH,测试模型的步骤决策正确性;
- GUI 定位评估:基于 OSWorld-G、ScreenSpot-Pro、UI-Vision 等基准,测试模型将自然语言指令映射为具体 GUI 操作的能力,这是 CUA 完成任务的基础。
二、OPENCUA 的核心实现效果:刷新开源 CUA 性能纪录,泛化性与可扩展性突出
基于上述技术路径,OPENCUA 推出了多参数量模型版本(7B/32B/72B),在各类 CUA 基准上取得了开源模型最优性能,并展现出优秀的泛化性、可扩展性,大幅缩小了与闭源模型的差距。
-
线上执行性能:OPENCUA-72B 创开源纪录,逼近闭源模型
在核心基准 OSWorld-Verified(100 步限制)上,OPENCUA-72B 达到 45.0% 的成功率,成为开源 CUA 模型的新标杆,超越此前的 UI-TARS-72B-DPO(27.1%)、Qwen3-VL(38.1%)等方案;同时其性能已逼近闭源模型 Claude 4 Sonnet(43.9%),仅落后于最新的 Claude Sonnet 4.5(61.4%),大幅缩小了开源与闭源 CUA 的性能差距。
不同参数量的 OPENCUA 模型呈现出清晰的规模效应:7B 版本达到 26.6% 的成功率,32B 版本提升至 34.8%,72B 版本进一步突破 45%,验证了训练流水线对模型参数量的良好适配性。 -
多维度能力领先,定位与推理双优
OPENCUA 模型不仅端到端执行能力突出,在 GUI 定位这一基础能力上也刷新了开源纪录:- OPENCUA-72B 在 ScreenSpot-Pro(高分辨率桌面 GUI 定位)上达到 60.8% 的准确率,在 UI-Vision(专业软件复杂定位)上达到 37.3% 的准确率,均为开源模型最优;
- 32B/7B 版本也表现出竞争力,证明 OPENCUA 的训练方案可在不同参数量级下实现能力提升。
同时,在离线基准 AGENTNETBENCH 上,OPENCUA-32B 达到 79.1% 的平均成功率,远超开源基础模型(如 Qwen2.5-VL-72B 为 67.0%),甚至逼近闭源模型 OpenAI CUA(75.2%),验证了模型的推理决策能力。
-
优秀的泛化性与可扩展性,支撑规模化应用
- 跨域泛化:基于跨平台、多领域的 AGENTNET 数据集训练后,OPENCUA 模型在未见过的应用、网站、操作系统上仍能保持较好性能,例如在 Ubuntu 上训练的模型可迁移至 Windows,应用级知识的跨平台迁移能力突出;
- 数据规模化效应:模型性能随训练数据规模线性提升 ——Ubuntu 数据从 3K 增至 10K,模型平均性能提升 72%;Win/Mac 数据从 3K 增至 14K,性能提升 125%,且跨域数据(如 Win/Mac 数据用于 Ubuntu 任务)不会产生负迁移,反而能提升模型的通用推理能力;
- 测试时计算增益:模型在 Pass@n 评估中表现出大幅提升,OPENCUA-72B 的 Pass@3 成功率达到 53.2%(较 Pass@1 的 45.0% 提升 8.2 个百分点),说明模型存在大量优质候选操作,为后续重排序、多智能体协作等方案预留了优化空间。
三、OPENCUA 的方法优劣分析:核心优势突出,仍存可优化空间
OPENCUA 作为首个全链路开源的 CUA 框架,为行业提供了可复现、可扩展的技术底座,其方法设计的优势十分显著,但同时也存在一些现阶段的局限性,为后续研究指明了方向。
核心优势
- 全链路开源,解决行业透明性痛点:OPENCUA 开源了标注工具、数据集、代码、模型、评估基准全套资源,是目前最完整的 CUA 开源方案,让研究团队无需重复造轮子,可直接在其基础上进行二次创新,大幅降低 CUA 研究的准入门槛;
- 反思式长链推理,赋予模型错误恢复能力:相较于传统 CUA 仅关注 “正确操作模仿”,OPENCUA 主动利用人类操作中的错误,通过反射器合成反思推理,让模型能识别自身操作错误并调整规划,这是其性能超越现有方案的核心原因之一,也更贴合人类的操作逻辑;
- 跨平台、大规模的数据集,支撑泛化性:AGENTNET 数据集是首个覆盖三大桌面系统、多领域应用的大规模 CUA 数据集,真实还原了人类的复杂操作场景,从数据源头解决了传统模型泛化性不足的问题;
- 灵活的训练方案,适配不同算力需求:提供三种训练策略,兼顾轻量适配与高性能训练,无论是算力有限的小团队还是具备大规模算力的机构,都能基于 OPENCUA 构建自己的 CUA 模型,提升了框架的实用性。
现阶段局限性
- 数据集规模受人类标注限制:AGENTNET 数据集的 22.6K 轨迹依赖人工标注,虽然标注工具已大幅提升效率,但进一步扩大数据集仍需大量人力成本,且标注者难以覆盖所有专业领域的操作技巧(如快捷键、脚本编写);
- 长程任务能力仍有不足:尽管模型具备一定的错误恢复能力,但在超过 50 步的长程任务中,性能提升有限,且容易出现操作重复、上下文丢失的问题,核心原因是模型的长程记忆与规划能力仍需加强;
- 高精度定位任务表现欠佳:在需要像素级精准操作的任务中(如将 “H2O” 中的 “2” 设为下标),模型的定位误差较高,这类细粒度 GUI 操作的训练数据仍较为缺乏;
- 环境动态性适应能力弱:模型对环境的微小变化(如系统日期、窗口位置)较为敏感,即使初始状态仅有细微差异,也可能导致最终任务失败,鲁棒性仍需提升。
四、总结与行业启示
OPENCUA 的推出,不仅刷新了开源 CUA 的性能纪录,更重要的是为行业构建了开放、可复现的 CUA 研究基础,解决了闭源体系下技术迭代慢、安全风险不可控的痛点。
其核心创新 —— 反思式长链推理、跨平台大规模数据集、灵活的多阶段训练策略,为后续 CUA 研究提供了重要的技术参考。
从行业发展来看,OPENCUA 验证了 “数据规模化 + 推理结构化” 是 CUA 能力提升的核心路径,未来的研究方向可围绕以下几点展开:
- 半自动化 / 自动化数据生成:结合大模型生成虚拟操作轨迹,弥补人工标注的规模与领域限制;
- 增强长程记忆与规划:引入记忆网络、分层规划等技术,提升模型在长程任务中的表现;
- 高精度 GUI 定位优化:收集细粒度定位数据,结合视觉特征增强,提升像素级操作能力;
- 多智能体协作:利用 OPENCUA 的 Pass@n 增益,构建多智能体协作框架,通过重排序、投票提升任务成功率。
目前,OPENCUA 的全套资源已在https://opencua.xlang.ai开源,相信这一框架将推动 CUA 研究进入更开放、更高效的新阶段,让智能体真正成为人类数字生活的可靠助手。