
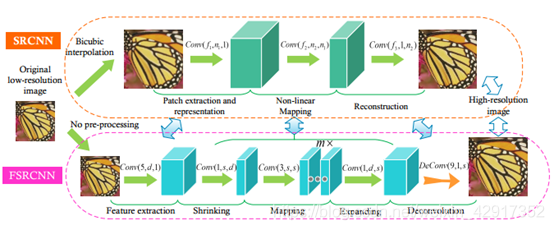
– 对之前SRCNN算法的改进
- 输出层采用转置卷积层放大尺寸,这样可以直接将低分辨率图片输入模型中,解决了输入尺度问题。
- 改变特征维数,使用更小的卷积核和使用更多的映射层。卷积核更小,加入了更多的激活层。
- 共享其中的映射层,如果需要训练不同上采样倍率的模型,只需要修改最后的反卷积层大小,就可以训练出不同尺寸的图片。
- 模型实现
import math
from torch import nn
class FSRCNN(nn.Module):
def __init__(self, scale_factor, num_channels=1, d=56, s=12, m=4):
super(FSRCNN, self).__init__()
self.first_part = nn.Sequential(
nn.Conv2d(num_channels, d, kernel_size=5, padding=5//2),
nn.PReLU(d)
)
# 添加入多个激活层和小卷积核
self.mid_part = [nn.Conv2d(d, s, kernel_size=1), nn.PReLU(s)]
for _ in range(m):
self.mid_part.extend([nn.Conv2d(s, s, kernel_size=3, padding=3//2), nn.PReLU(s)])
self.mid_part.extend([nn.Conv2d(s, d, kernel_size=1), nn.PReLU(d)])
self.mid_part = nn.Sequential(*self.mid_part)
# 最后输出
self.last_part = nn.ConvTranspose2d(d, num_channels, kernel_size=9, stride=scale_factor, padding=9//2,
output_padding=scale_factor-1)
self._initialize_weights()
def _initialize_weights(self):
# 初始化
for m in self.first_part:
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight.data, mean=0.0, std=math.sqrt(2/(m.out_channels*m.weight.data[0][0].numel())))
nn.init.zeros_(m.bias.data)
for m in self.mid_part:
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight.data, mean=0.0, std=math.sqrt(2/(m.out_channels*m.weight.data[0][0].numel())))
nn.init.zeros_(m.bias.data)
nn.init.normal_(self.last_part.weight.data, mean=0.0, std=0.001)
nn.init.zeros_(self.last_part.bias.data)
def forward(self, x):
x = self.first_part(x)
x = self.mid_part(x)
x = self.last_part(x)
return x
以上代码中,如起初所说,将SRCNN中给的输出修改为转置卷积,并且在中间添加了多个11卷积核和多个线性激活层。且应用了权重初始化,解决协变量偏移问题。 备注:11卷积核虽然在通道的像素层面上,针对一个像素进行卷积,貌似没有什么作用,但是卷积神经网络的特性,我们在利用多个卷积核对特征图进行扫描时,单个卷积核扫描后的为sum©,那么就是尽管在像素层面上无用,但是在通道层面上进行了融合,并且进一步加深了层数,使网络层数增加,网络能力增强。
- 上代码
- train.py
训练脚本
import argparse
import os
import copy
import torch
from torch import nn
import torch.optim as optim
import torch.backends.cudnn as cudnn
from torch.utils.data.dataloader import DataLoader
from tqdm import tqdm
from models import FSRCNN
from datasets import TrainDataset, EvalDataset
from utils import AverageMeter, calc_psnr
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# 训练文件
parser.add_argument('--train-file', type=str,help="the dir of train data",default="./Train/91-image_x4.h5")
# 测试集文件
parser.add_argument('--eval-file', type=str,help="thr dir of test data ",default="./Test/Set5_x4.h5")
# 输出的文件夹
parser.add_argument('--outputs-dir',help="the output dir", type=str,default="./outputs")
parser.add_argument('--weights-file', type=str)
parser.add_argument('--scale', type=int, default=2)
parser.add_argument('--lr', type=float, default=1e-3)
parser.add_argument('--batch-size', type=int, default=16)
parser.add_argument('--num-epochs', type=int, default=20)
parser.add_argument('--num-workers', type=int, default=8)
parser.add_argument('--seed', type=int, default=123)
args = parser.parse_args()
args.outputs_dir = os.path.join(args.outputs_dir, 'x{}'.format(args.scale))
if not os.path.exists(args.outputs_dir):
os.makedirs(args.outputs_dir)
cudnn.benchmark = True
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
torch.manual_seed(args.seed)
model = FSRCNN(scale_factor=args.scale).to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam([
{'params': model.first_part.parameters()},
{'params': model.mid_part.parameters()},
{'params': model.last_part.parameters(), 'lr': args.lr * 0.1}
], lr=args.lr)
train_dataset = TrainDataset(args.train_file)
train_dataloader = DataLoader(dataset=train_dataset,
batch_size=args.batch_size,
shuffle=True,
num_workers=args.num_workers,
pin_memory=True)
eval_dataset = EvalDataset(args.eval_file)
eval_dataloader = DataLoader(dataset=eval_dataset, batch_size=1)
best_weights = copy.deepcopy(model.state_dict())
best_epoch = 0
best_psnr = 0.0
for epoch in range(args.num_epochs):
model.train()
epoch_losses = AverageMeter()
with tqdm(total=(len(train_dataset) - len(train_dataset) % args.batch_size), ncols=80) as t:
t.set_description('epoch: {}/{}'.format(epoch, args.num_epochs - 1))
for data in train_dataloader:
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
preds = model(inputs)
loss = criterion(preds, labels)
epoch_losses.update(loss.item(), len(inputs))
optimizer.zero_grad()
loss.backward()
optimizer.step()
t.set_postfix(loss='{:.6f}'.format(epoch_losses.avg))
t.update(len(inputs))
torch.save(model.state_dict(), os.path.join(args.outputs_dir, 'epoch_{}.pth'.format(epoch)))
model.eval()
epoch_psnr = AverageMeter()
for data in eval_dataloader:
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
with torch.no_grad():
preds = model(inputs).clamp(0.0, 1.0)
epoch_psnr.update(calc_psnr(preds, labels), len(inputs))
print('eval psnr: {:.2f}'.format(epoch_psnr.avg))
if epoch_psnr.avg > best_psnr:
best_epoch = epoch
best_psnr = epoch_psnr.avg
best_weights = copy.deepcopy(model.state_dict())
print('best epoch: {}, psnr: {:.2f}'.format(best_epoch, best_psnr))
torch.save(best_weights, os.path.join(args.outputs_dir, 'best.pth'))
test.py 测试脚本
import argparse
import torch
import torch.backends.cudnn as cudnn
import numpy as np
import PIL.Image as pil_image
from models import FSRCNN
from utils import convert_ycbcr_to_rgb, preprocess, calc_psnr
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights-file', type=str, required=True)
parser.add_argument('--image-file', type=str, required=True)
parser.add_argument('--scale', type=int, default=3)
args = parser.parse_args()
cudnn.benchmark = True
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = FSRCNN(scale_factor=args.scale).to(device)
state_dict = model.state_dict()
for n, p in torch.load(args.weights_file, map_location=lambda storage, loc: storage).items():
if n in state_dict.keys():
state_dict[n].copy_(p)
else:
raise KeyError(n)
model.eval()
image = pil_image.open(args.image_file).convert('RGB')
image_width = (image.width // args.scale) * args.scale
image_height = (image.height // args.scale) * args.scale
hr = image.resize((image_width, image_height), resample=pil_image.BICUBIC)
lr = hr.resize((hr.width // args.scale, hr.height // args.scale), resample=pil_image.BICUBIC)
bicubic = lr.resize((lr.width * args.scale, lr.height * args.scale), resample=pil_image.BICUBIC)
bicubic.save(args.image_file.replace('.', '_bicubic_x{}.'.format(args.scale)))
lr, _ = preprocess(lr, device)
hr, _ = preprocess(hr, device)
_, ycbcr = preprocess(bicubic, device)
with torch.no_grad():
preds = model(lr).clamp(0.0, 1.0)
psnr = calc_psnr(hr, preds)
print('PSNR: {:.2f}'.format(psnr))
preds = preds.mul(255.0).cpu().numpy().squeeze(0).squeeze(0)
output = np.array([preds, ycbcr[..., 1], ycbcr[..., 2]]).transpose([1, 2, 0])
output = np.clip(convert_ycbcr_to_rgb(output), 0.0, 255.0).astype(np.uint8)
output = pil_image.fromarray(output)
# 保存图片
output.save(args.image_file.replace('.', '_fsrcnn_x{}.'.format(args.scale)))
datasets.py
数据集的读取
import h5py
import numpy as np
from torch.utils.data import Dataset
class TrainDataset(Dataset):
def __init__(self, h5_file):
super(TrainDataset, self).__init__()
self.h5_file = h5_file
def __getitem__(self, idx):
with h5py.File(self.h5_file, 'r') as f:
return np.expand_dims(f['lr'][idx] / 255., 0), np.expand_dims(f['hr'][idx] / 255., 0)
def __len__(self):
with h5py.File(self.h5_file, 'r') as f:
return len(f['lr'])
class EvalDataset(Dataset):
def __init__(self, h5_file):
super(EvalDataset, self).__init__()
self.h5_file = h5_file
def __getitem__(self, idx):
with h5py.File(self.h5_file, 'r') as f:
return np.expand_dims(f['lr'][str(idx)][:, :] / 255., 0), np.expand_dims(f['hr'][str(idx)][:, :] / 255., 0)
def __len__(self):
with h5py.File(self.h5_file, 'r') as f:
return len(f['lr'])
工具文件utils.py
- 主要用来测试psnr指数,图片的格式转换(悄悄说一句,opencv有直接实现~~~)
import torch
import numpy as np
def calc_patch_size(func):
def wrapper(args):
if args.scale == 2:
args.patch_size = 10
elif args.scale == 3:
args.patch_size = 7
elif args.scale == 4:
args.patch_size = 6
else:
raise Exception('Scale Error', args.scale)
return func(args)
return wrapper
def convert_rgb_to_y(img, dim_order='hwc'):
if dim_order == 'hwc':
return 16. + (64.738 * img[..., 0] + 129.057 * img[..., 1] + 25.064 * img[..., 2]) / 256.
else:
return 16. + (64.738 * img[0] + 129.057 * img[1] + 25.064 * img[2]) / 256.
def convert_rgb_to_ycbcr(img, dim_order='hwc'):
if dim_order == 'hwc':
y = 16. + (64.738 * img[..., 0] + 129.057 * img[..., 1] + 25.064 * img[..., 2]) / 256.
cb = 128. + (-37.945 * img[..., 0] - 74.494 * img[..., 1] + 112.439 * img[..., 2]) / 256.
cr = 128. + (112.439 * img[..., 0] - 94.154 * img[..., 1] - 18.285 * img[..., 2]) / 256.
else:
y = 16. + (64.738 * img[0] + 129.057 * img[1] + 25.064 * img[2]) / 256.
cb = 128. + (-37.945 * img[0] - 74.494 * img[1] + 112.439 * img[2]) / 256.
cr = 128. + (112.439 * img[0] - 94.154 * img[1] - 18.285 * img[2]) / 256.
return np.array([y, cb, cr]).transpose([1, 2, 0])
def convert_ycbcr_to_rgb(img, dim_order='hwc'):
if dim_order == 'hwc':
r = 298.082 * img[..., 0] / 256. + 408.583 * img[..., 2] / 256. - 222.921
g = 298.082 * img[..., 0] / 256. - 100.291 * img[..., 1] / 256. - 208.120 * img[..., 2] / 256. + 135.576
b = 298.082 * img[..., 0] / 256. + 516.412 * img[..., 1] / 256. - 276.836
else:
r = 298.082 * img[0] / 256. + 408.583 * img[2] / 256. - 222.921
g = 298.082 * img[0] / 256. - 100.291 * img[1] / 256. - 208.120 * img[2] / 256. + 135.576
b = 298.082 * img[0] / 256. + 516.412 * img[1] / 256. - 276.836
return np.array([r, g, b]).transpose([1, 2, 0])
def preprocess(img, device):
img = np.array(img).astype(np.float32)
ycbcr = convert_rgb_to_ycbcr(img)
x = ycbcr[..., 0]
x /= 255.
x = torch.from_numpy(x).to(device)
x = x.unsqueeze(0).unsqueeze(0)
return x, ycbcr
def calc_psnr(img1, img2):
return 10. * torch.log10(1. / torch.mean((img1 - img2) ** 2))
class AverageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count